法律翻譯、術語庫 (Glossary)、翻譯記憶庫 (TM)
在今日的法律服務市場上,多語言合約翻譯變得日益重要。想像一家律師事務所在處理 保密協議 (NDA)、勞動合約、公司章程等法律文件時,經常需要提供中英或中日雙語版本給國際客戶。
傳統上仰賴人工翻譯不僅費時費力,也存在用詞不一致或潛在誤譯的風險。一份合約動輒數十頁,譯者必須精準掌握法律術語並保持前後一致,稍有不慎就可能引發法律糾紛。
為了提升效率與降低風險,為 Odoo 法律專案導入 AI 翻譯引擎:透過 生成式 AI 模型自動將中文法律條款翻譯成英文與日文,並確保專業術語精準轉換,打造多語言法律翻譯引擎,讓律所能快速且一致地產出高品質雙語合約。
為了將 AI 翻譯無縫融合進 Odoo,我們採用模組化與服務化的架構:
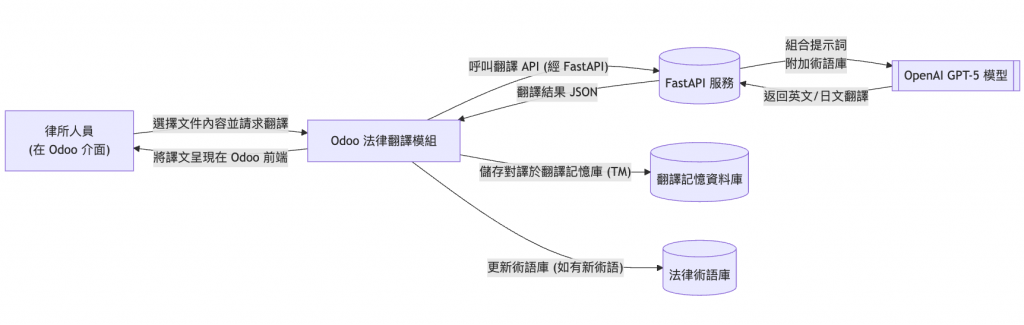
上述架構中,我們開發一個 Odoo 自訂模組(如 legal_translation),提供介面讓使用者選取中文原文並請求翻譯。
Odoo 模組將請求發送給獨立的 FastAPI 服務,此服務負責與 OpenAI 模型交互。在 FastAPI 中,我們可以靈活地組裝 提示詞 (prompt) —— 包括將法律術語對照表作為參考,然後呼叫 OpenAI 的 GPT-5 API 完成翻譯。
翻譯完成後,FastAPI 以結構化資料(例如 JSON)形式將結果傳回 Odoo。Odoo 模組接收結果後,除了顯示譯文,還會將中譯對照存入翻譯記憶庫,以便後續相似句子可以重用之前的翻譯,確保一貫性並節省成本。同時,如果在翻譯過程中發現新的法律術語,系統也可以提示將其加入術語庫中,逐步完善我們的專業詞彙表。
上述方法透過分離關注點達成彈性設計:Odoo 前端專注於使用者體驗與資料儲存,FastAPI 後端專注於AI請求與術語處理。我們避免讓 Odoo 直接調用外部API,以免主系統執行緒受阻;取而代之的是使用 FastAPI 作為中介,未來無論是更換模型或調整提示詞,對 Odoo 主程式碼的影響都降至最低。
在 FastAPI 服務中,我們設計了兩個主要端點:一個 /translate 用於接收翻譯請求並呼叫 OpenAI API,另一個 /glossary 用於管理術語庫資料(例如新增/更新法律專有名詞對譯表)。
/translate 端點的簡化範例:from fastapi import FastAPI
from pydantic import BaseModel
import openai
from glossary_json_service import _load as load_legal_glossary
app = FastAPI()
openai.api_key = "<YOUR_OPENAI_API_KEY>"
class TranslateRequest(BaseModel):
text: str
target_lang: str # e.g., "en" or "ja"
@app.post("/translate")
def translate_text(req: TranslateRequest):
# 1. 取得最新法律術語對照表,例如字典形式 {"終止": {"en": "terminate", "ja": "解除"} ...}
glossary = load_legal_glossary()
# 2. 組合提示詞:說明角色與任務,提供 Glossary 參考,附上用戶輸入的原文
system_prompt = (
"你是一個專業的法律文件翻譯助手。請將給定的中文法律條款翻譯為" +
("英文" if req.target_lang == "en" else "日文") +
",用詞正式且精確。請嚴格依照下列術語對照翻譯專有名詞:\n" +
"\n".join([f"{term}: {trans[req.target_lang]}" for term, trans in glossary.items()]) +
"\n翻譯時保持條款結構完整,不要遺漏任何內容,也不添加額外說明。"
)
# 3. 呼叫 OpenAI
response = openai.ChatCompletion.create(
model="gpt-5",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": req.text}
],
temperature=0 # 設定低溫度,翻譯需精確而非創意
)
# 4. 解析模型回傳內容
translated_text = response['choices'][0]['message']['content']
# 5. 將結果包裝並返回
return {"translation": translated_text}
上述程式說明了 FastAPI 如何串接 OpenAI 模型並應用術語庫資訊:我們從資料庫或檔案載入預先建立的法律術語對照表(例如 glossary = {"終止": {"en": "terminate", "ja": "解除"}, ...}),然後在 system_prompt 中明確列出這些詞彙的翻譯要求,讓 GPT 模型在處理時有據可依。我們也透過 temperature=0 來降低隨機性,以確保輸出結果更可預測(這在法律翻譯中特別重要,因為我們寧可要可靠一致的翻譯,而非充滿創意的改寫)。最後將翻譯結果以 JSON 格式返回給 Odoo 模組。
/glossary 端點的簡化範例:這邊用 JSON 檔維護 Glossary(輕量、好上手),正式一點的話還是推薦使用資料庫儲存。
# glossary_json_service.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field, constr
from typing import Dict, Optional, List
from datetime import datetime
import json, os, threading
app = FastAPI(title="Legal Glossary Service (JSON)")
GLOSSARY_PATH = os.getenv("GLOSSARY_PATH", "./glossary.json")
_lock = threading.Lock()
class TermTranslations(BaseModel):
en: Optional[constr(strip_whitespace=True)] = None
ja: Optional[constr(strip_whitespace=True)] = None
class GlossaryEntry(BaseModel):
term: constr(strip_whitespace=True, min_length=1) # 中文關鍵詞(索引鍵)
translations: TermTranslations = Field(default_factory=TermTranslations)
note: Optional[str] = None # 備註說明(來源、用法)
source: Optional[str] = None # 來源(ex: 內部標準、法院見解)
updated_at: datetime = Field(default_factory=datetime.utcnow)
def _load() -> Dict[str, GlossaryEntry]:
if not os.path.exists(GLOSSARY_PATH):
return {}
with _lock, open(GLOSSARY_PATH, "r", encoding="utf-8") as f:
raw = json.load(f)
# 反序列化
data: Dict[str, GlossaryEntry] = {}
for k, v in raw.items():
data[k] = GlossaryEntry(**v)
return data
def _save(data: Dict[str, GlossaryEntry]) -> None:
# 序列化(Pydantic -> dict)
serializable = {k: v.model_dump() for k, v in data.items()}
with _lock, open(GLOSSARY_PATH, "w", encoding="utf-8") as f:
json.dump(serializable, f, ensure_ascii=False, indent=2, default=str)
@app.get("/glossary", response_model=List[GlossaryEntry])
def list_terms(q: Optional[str] = None):
"""
取得全部術語;可用 ?q=關鍵字 做前綴/子字串篩選
"""
data = _load()
out = list(data.values())
if q:
q = q.strip()
out = [e for e in out if q in e.term or (e.note and q in e.note)]
return sorted(out, key=lambda e: e.term)
@app.get("/glossary/{term}", response_model=GlossaryEntry)
def get_term(term: str):
data = _load()
if term not in data:
raise HTTPException(status_code=404, detail="Term not found")
return data[term]
@app.post("/glossary", response_model=GlossaryEntry, status_code=201)
def upsert_term(entry: GlossaryEntry):
"""
新增或更新(Upsert)
- 若 term 存在則更新 translations/note/source 並覆蓋 updated_at
- 請保證 term 是「中文關鍵詞」,translations.en/ja 為對應譯法
"""
data = _load()
now = datetime.utcnow()
if entry.term in data:
current = data[entry.term]
# 合併更新:若欄位有提供才覆蓋
if entry.translations.en is not None:
current.translations.en = entry.translations.en
if entry.translations.ja is not None:
current.translations.ja = entry.translations.ja
if entry.note is not None:
current.note = entry.note
if entry.source is not None:
current.source = entry.source
current.updated_at = now
data[entry.term] = current
_save(data)
return current
else:
entry.updated_at = now
data[entry.term] = entry
_save(data)
return entry
@app.delete("/glossary/{term}", status_code=204)
def delete_term(term: str):
data = _load()
if term not in data:
raise HTTPException(status_code=404, detail="Term not found")
data.pop(term)
_save(data)
在上述 FastAPI 流程中,Glossary 術語庫介面的作用不可或缺。我們在 /glossary 端點實作允許管理者新增或更新術語,例如透過簡單的 POST 請求上傳新的詞彙及其翻譯。這些術語會存放在資料庫中供 load_legal_glossary() 使用。如此一來,即使法律條款出現新的專業用語,我們也能動態更新對照表,而無需重新部署模型或改動主要代碼。這種結構讓系統具有持續學習的能力:隨著使用越多,術語庫越完整,翻譯質量也會同步提升。
💡 Gary’s Pro Tip|用 JSON 檔維護知識、術語庫
- 初次啟動可建立
glossary.json空檔{},避免讀檔失敗。- 若擔心併發寫入,可維持
_lock或改用檔案鎖 (file lock)。- 加上簡單備份:每次
_save先把舊檔 rename 成glossary.json.bak。
法律文件中充斥著專門用語和制式表述,翻譯這些詞彙是AI面臨的最大挑戰之一。我們以幾個具代表性的英文術語為例,說明它們在中日翻譯中的精準對應及處理方式:
上述每個術語的精準翻譯都至關重要。稍有不慎,用詞不當可能導致法律效力的改變。透過術語庫的建立,我們相當於為 AI 準備了一本法律字典。在翻譯時,先比對原文中是否包含 Glossary 裡的關鍵詞,若有則使用對應翻譯;如果模型對上下文判斷有所偏差,我們的提示詞也會加強糾正。例如,我們可以在 prompt 中加入:「注意:"終止"在法律語境固定譯為"terminate",請勿使用其他同義字」。這種明示能顯著提高專業用語的一致性。
Glossary 術語庫的建設是一項持續工程。我們初始從歷史翻譯資料和法律辭典中整理出常見詞彙對譯清單,涵蓋公司法、勞動法、商業合約等領域。
例如,建立一份 CSV 或 Excel,其中包含「中文術語 | 英文對譯 | 日文對譯 | 備註」。接著,我們開發 Odoo 模組或後端介面讓法務人員可隨時更新這份術語庫。每當遇到GPT翻譯不理想的術語,就將更正後的譯法加入庫中,未來模型便能參照使用。
關鍵在於將術語庫融入提示詞。如前節程式碼所示,我們把 Glossary 條目拼接進 system message,這樣 GPT 模型在生成翻譯時會明確看到每個詞的指導翻譯。這種方式有點類似傳統機器翻譯中的「用戶詞典」或「術語記憶」功能。然而,OpenAI 的 GPT 模型並沒有直接的術語表匯入功能,需要透過微調 (fine-tuning) 或提示工程實現。由於微調門檻較高且需要定期更新,我們採用提示工程為主、微調為輔的策略:當術語庫較小時,以 prompt 引導。
在 Odoo 自訂模組中,你可以加入一個簡單的按鈕或排程:按一下就呼叫 FastAPI /glossary 導入新詞,或根據審核結果把修訂後的用語 upsert 回去。
# models/legal_glossary_sync.py
from odoo import models, fields, api, _
import requests
class LegalGlossarySync(models.TransientModel):
_name = "legal.glossary.sync.wizard"
_description = "同步/更新 法律術語庫"
term = fields.Char("中文術語", required=True)
en = fields.Char("英文譯法")
ja = fields.Char("日文譯法")
note = fields.Char("備註")
source = fields.Char("來源")
def action_upsert_to_api(self):
payload = {
"term": self.term,
"translations": {"en": self.en, "ja": self.ja},
"note": self.note or "",
"source": self.source or "",
}
res = requests.post("http://ai-server:8000/glossary", json=payload, timeout=8)
if res.status_code not in (200, 201):
raise UserError(_("Glossary upsert failed: %s") % res.text)
self.env.user.notify_success(message=_("Glossary updated: %s") % self.term)
💡 Gary’s Pro Tip|持續維護術語庫
確保術語庫長期有效的秘訣在於動態維護和介入檢核。建議定期審視翻譯結果,將新的或錯譯的術語補充到 Glossary 中,並且不要將術語表硬編碼在程式中。最好每次翻譯請求都從資料庫讀取最新術語,這樣即使術語庫頻繁更新,模型提示也能隨之調整,避免出現「舊術語表無法覆蓋新需求」的問題。此外,可以建立審核流程:如每月由法律專家審查術語庫的譯法,確保隨著法律趨勢變化或客戶偏好調整,我們的 Glossary 依然適用。
有了初步的翻譯結果後,仍需要對其進行品質檢查 (QA),尤其在法律領域,任何細節偏差都可能產生重大影響。我們採取了多層次的自動 QA 與對譯比對方法:
下面提供自動 QA 示例程式碼:
# qa_minimal.py
from typing import Dict, List, Optional, Tuple
from dataclasses import dataclass, asdict
import os, re, json
# ==============
# 基本抽取規則
# ==============
CN_DATE = r"(?:\d{4}年\d{1,2}月\d{1,2}日|\d{4}年\d{1,2}月|\d{1,2}月\d{1,2}日)"
EN_DATE = r"(?:\b(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Sept|Oct|Nov|Dec)[a-z]*\.?\s+\d{1,2},\s*\d{4}\b|\b\d{4}-\d{1,2}-\d{1,2}\b|\b\d{1,2}/\d{1,2}/\d{2,4}\b)"
JA_DATE = r"(?:\d{4}年\d{1,2}月\d{1,2}日)"
NUMBER = r"(?:\b\d{1,3}(?:,\d{3})*(?:\.\d+)?\b|\b\d+(?:\.\d+)?\b)"
EN_PROPER = r"\b[A-Z][A-Za-z0-9&.\-]*(?:\s+[A-Z][A-Za-z0-9&.\-]*)*\b"
def extract_entities_zh(text: str):
return {
"numbers": re.findall(NUMBER, text),
"dates": re.findall(CN_DATE, text),
}
def extract_entities_en(text: str):
return {
"numbers": re.findall(NUMBER, text),
"dates": re.findall(EN_DATE, text),
"names": re.findall(EN_PROPER, text),
}
def extract_entities_ja(text: str):
return {
"numbers": re.findall(NUMBER, text),
"dates": re.findall(JA_DATE, text),
}
# ==============
# QA 資料模型
# ==============
@dataclass
class TMEntry:
src: str
tgt: str
lang: str # "en" | "ja"
@dataclass
class Issue:
type: str
message: str
meta: Dict[str, str]
@dataclass
class QAResult:
ok: bool
issues: List[Issue]
scores: Dict[str, float] # glossary/number/date/name/tm/back
# =====================
# 1) 關鍵術語檢查 (Glossary)
# =====================
def qa_glossary(source_cn: str,
target_text: str,
target_lang: str,
glossary: Dict[str, Dict[str, Optional[str]]]) -> Tuple[float, List[Issue]]:
"""
glossary: 形如 {"終止": {"en":"terminate","ja":"解除"}, ...}
檢查:原文出現的中文術語,其對應的指定譯法應出現在譯文中
"""
issues: List[Issue] = []
tgt_norm = target_text.lower()
total, ok_count = 0, 0
for term_cn, mapping in glossary.items():
if term_cn in source_cn:
total += 1
expect = (mapping.get(target_lang) or "").strip()
if not expect:
ok_count += 1 # 該語向未定義,跳過不扣分
continue
if expect.lower() in tgt_norm:
ok_count += 1
else:
issues.append(Issue(
type="glossary_miss",
message=f"Glossary 未套用:{term_cn} → 期望 {target_lang}='{expect}'",
meta={"term": term_cn, "expected": expect}
))
score = ok_count / total if total else 1.0
return score, issues
# ===============================
# 2) 完整性與數據檢查(數字/日期/專名)
# ===============================
def _coverage_match(src_list: List[str], tgt_list: List[str], normalize_num=False):
src = set(s.strip() for s in src_list if s.strip())
tgt = set(t.strip() for t in tgt_list if t.strip())
if normalize_num:
norm = lambda x: x.replace(",", "")
src = set(map(norm, src)); tgt = set(map(norm, tgt))
miss = [s for s in src if not any(s in t or t in s for t in tgt)]
hits = len(src) - len(miss)
score = hits / len(src) if src else 1.0
return score, miss
def qa_integrity(source_cn: str, target_text: str, target_lang: str) -> Tuple[Dict[str, float], List[Issue]]:
issues: List[Issue] = []
zh = extract_entities_zh(source_cn)
if target_lang == "en":
tr = extract_entities_en(target_text)
else:
tr = extract_entities_ja(target_text)
num_score, num_miss = _coverage_match(zh["numbers"], tr["numbers"], normalize_num=True)
date_score, date_miss = _coverage_match(zh["dates"], tr["dates"], normalize_num=False)
# 英文譯文檢查是否有 Proper Noun(粗略作為專名存在感)
name_score = 1.0 if (target_lang != "en" or tr["names"]) else 0.8
for m in num_miss:
issues.append(Issue(type="number_miss", message=f"數字遺失:{m}", meta={"value": m}))
for m in date_miss:
issues.append(Issue(type="date_miss", message=f"日期遺失:{m}", meta={"value": m}))
return {"number": num_score, "date": date_score, "name": name_score}, issues
# ===============================
# 3) 反向翻譯(Back-translation,選用)
# ===============================
OPENAI_MODEL = "gpt-5"
def qa_back_translation(target_text: str, target_lang: str) -> Tuple[float, Optional[str]]:
"""
分數僅作預警用(0~1);此處以簡單長度/字符近似估計。
若開啟 OpenAI,可把 target_text 翻回中文,再做更精細比較。
"""
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
prompt = f"請將以下{target_lang.upper()} 法律譯文翻回繁體中文,不新增或刪除內容:\n\n{target_text}"
resp = openai.ChatCompletion.create(
model=OPENAI_MODEL,
messages=[{"role": "user", "content": prompt}],
temperature=0
)
back_cn = resp["choices"][0]["message"]["content"]
# 這裡你可以替換為 embeddings 等更嚴謹方法
ratio = min(len(back_cn), len(target_text)) / max(len(back_cn), len(target_text))
return float(f"{ratio:.3f}"), back_cn
# ==============================
# 4) TM(翻譯記憶)對譯比對
# ==============================
def qa_tm_consistency(source_cn: str, target_text: str, target_lang: str,
tm: List[TMEntry]) -> Tuple[float, List[Issue]]:
issues: List[Issue] = []
# 找出 TM 中完全相同的 src(可改為相似度查找)
gold = next((e for e in tm if e.lang == target_lang and e.src.strip() == source_cn.strip()), None)
if not gold:
return 1.0, issues
# 忽略大小寫+多空白差異
norm = lambda s: re.sub(r"\s+", " ", s).strip().lower()
if norm(gold.tgt) == norm(target_text):
return 1.0, issues
issues.append(Issue(
type="tm_inconsistent",
message="與 TM 既有譯文不一致",
meta={"expected": gold.tgt[:200] + ("..." if len(gold.tgt) > 200 else "")}
))
return 0.0, issues
# ==============================
# 聚合器:執行四項 QA 並輸出報告
# ==============================
def run_qa(source_cn: str,
target_text: str,
target_lang: str, # "en" | "ja"
glossary: Dict[str, Dict[str, Optional[str]]],
tm_entries: List[Dict]) -> Dict:
"""
tm_entries: [{"src":"中文句","tgt":"既有譯文","lang":"en"}, ...]
"""
tm = [TMEntry(**e) for e in tm_entries]
issues: List[Issue] = []
# 1) Glossary
gloss_score, gloss_issues = qa_glossary(source_cn, target_text, target_lang, glossary)
issues += gloss_issues
# 2) 數據/完整性
ent_scores, ent_issues = qa_integrity(source_cn, target_text, target_lang)
issues += ent_issues
# 3) 反向翻譯(可選)
back_score, back_text = qa_back_translation(target_text, target_lang)
# 4) TM 一致性
tm_score, tm_issues = qa_tm_consistency(source_cn, target_text, target_lang, tm)
issues += tm_issues
# 聚合分數(可調權重)
w = {"gloss": 0.35, "num": 0.15, "date": 0.15, "name": 0.05, "tm": 0.2, "back": 0.1}
overall = (
w["gloss"] * gloss_score +
w["num"] * ent_scores["number"] +
w["date"] * ent_scores["date"] +
w["name"] * ent_scores["name"] +
w["tm"] * tm_score +
w["back"] * (back_score or 0.0)
)
result = QAResult(
ok = overall >= 0.85 and gloss_score >= 0.9 and ent_scores["number"] >= 0.9 and ent_scores["date"] >= 0.9,
issues = issues,
scores = {
"glossary": round(gloss_score, 3),
"number": round(ent_scores["number"], 3),
"date": round(ent_scores["date"], 3),
"name": round(ent_scores["name"], 3),
"tm": round(tm_score, 3),
"back": round(back_score, 3) if back_score is not None else None,
"overall": round(overall, 3),
},
)
payload = asdict(result)
if back_text is not None:
payload["back_translation_preview"] = back_text[:400]
return payload
# =========
# 範例執行
# =========
if __name__ == "__main__":
src = "本協議自2025年1月1日起生效,違反保密義務者應負賠償責任。"
tgt = "This Agreement becomes effective on January 1, 2025, and any breach of confidentiality shall give rise to indemnity."
glossary = {
"生效": {"en": "effective", "ja": "発効"},
"賠償責任": {"en": "indemnity", "ja": "賠償責任"},
}
tm_entries = [
{"src": src, "tgt": "This Agreement shall become effective on January 1, 2025, and any breach of confidentiality shall give rise to indemnity.", "lang": "en"}
]
report = run_qa(src, tgt, "en", glossary, tm_entries)
print(json.dumps(report, ensure_ascii=False, indent=2))
值得一提的是,自動 QA 只能發現明顯的機械問題,最終仍需人工覆核法律譯文以確保精確無誤。法律文件的翻譯品質保障,需要嚴格的校對與審核流程。
AI 引擎目標是在機器處理80%的重複性工作,標記出可能問題,然後交由專業人員重點審查剩餘 20% 的細節。這種人機協作方式既能提升效率,又不犧牲專業水準。
今天我們介紹如何在 Odoo 上,打造了一個多語言法律翻譯引擎,使律所能更有效率地產出中英、中日雙語法律文件。
不僅透過 FastAPI 微服務架構讓整合更靈活,還利用法律術語庫確保專業術語的精準轉換和譯文的一致性。
AI 並非要取代人工翻譯,而是成為加速器和守門員——加速重複性工作,同時用術語庫和校驗機制守住品質底線。未來,隨著模型的不斷進步和我們術語資料的豐富,這套翻譯引擎將變得更加智能與可靠。


